COEN 210 Computer Architecture
Chapter 1 — Computer Abstraction and Technology
Understanding Performance
Algorithm
- Determines number of operations executed
Programming language, compiler, architecture
- Determine number of machine instructions executed per operation
Processor and memory system
- Determine how fast instructions are executed
I/O system (including OS)
- Determines how fast I/O operations are executed
Eight Great Ideas
- Design for Moore’s Law
- Use abstraction to simplify design
- Make the common case fast
- Performance via parallelism
- Performance via pipelining
- Performance via prediction
- Hierarchy of memories
- Dependability via redundancy
Pitfalls
Amdahl’s Law
- Improving an aspect of a computer and expecting a proportional improvement in overall performance
- Corollary: make the common case fast
Low Power at Idle
- Google data center
- Mostly operates at 10% – 50% load
- At 100% load less than 1% of the time
- Consider designing processors to make power proportional to load
- Google data center
MIPS as a Performance Metric
- MIPS: Millions of Instructions Per Second
- Doesn’t account for
- Differences in ISAs between computers
- Differences in complexity between instructions
Chapter 2 — Instructions: Language of the Computer
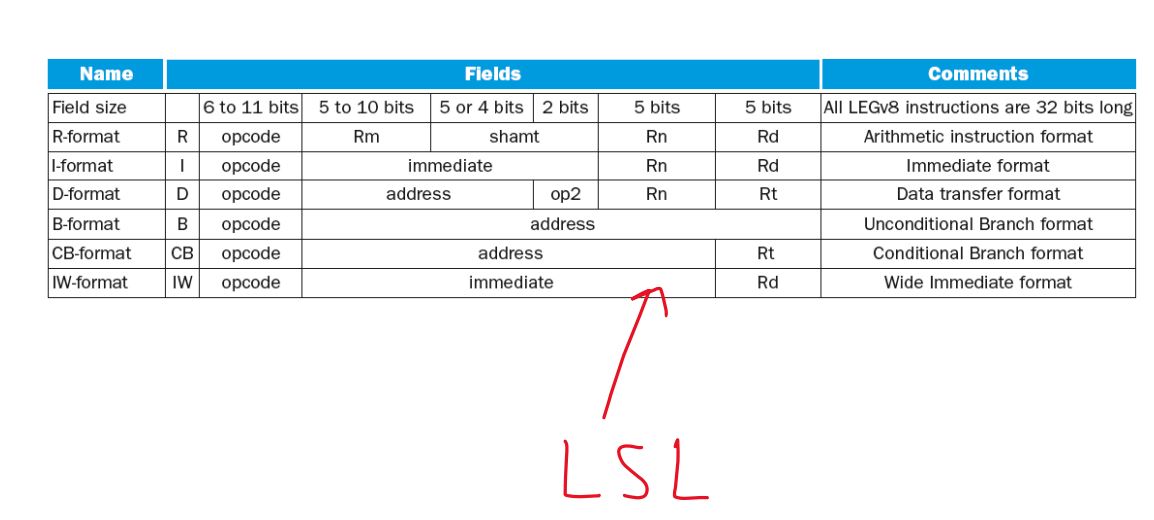
Design Principle
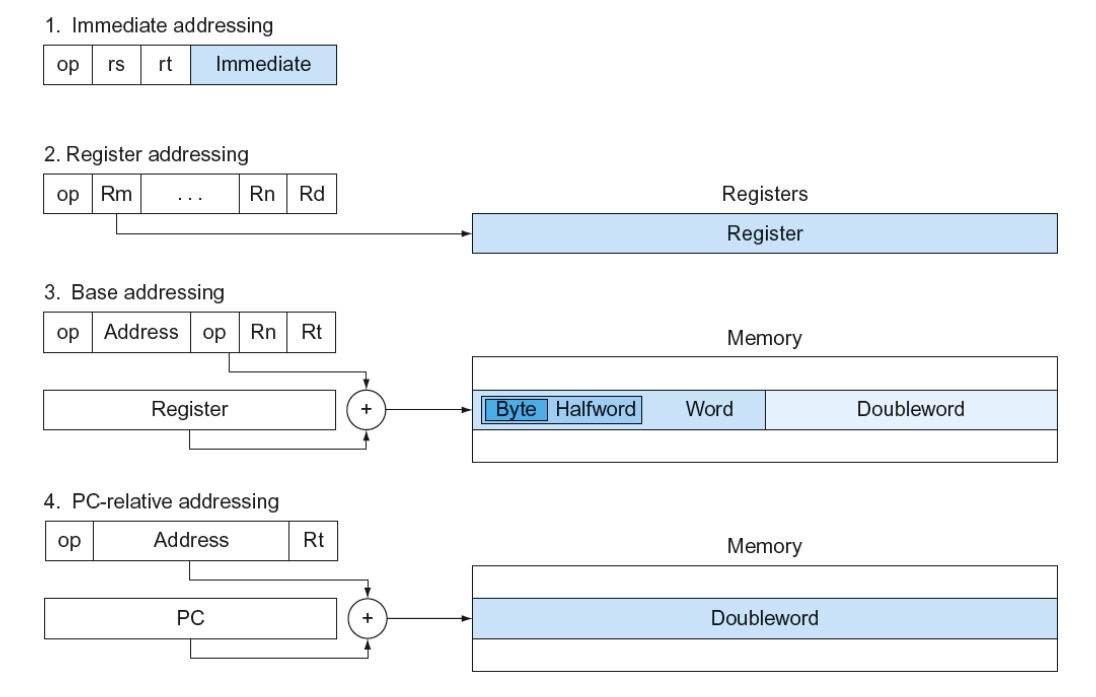
Simplicity favors regularity
All arithmetic operations have this form
ADD a, b, c // a = b + c
Regularity makes implementation simpler
Simplicity enables higher performance at lower cost
Smaller is faster
- LEGv8 has a 32 × 64-bit register file
- 64-bit data is called a “doubleword”
- 31 x 64-bit general purpose registers X0 to X30
- c.f. main memory: millions of locations
Make the common case fast
Constant data specified in an instruction
ADDI X22, X22, #4
Small constants are common
Immediate operand avoids a load instruction
Good design demands good compromises
- Different formats complicate decoding, but allow 32-bit instructions uniformly
- Keep formats as similar as possible
LEGv8 Registers
- X0 – X7: procedure arguments/results
- X8: indirect result location register
- X9 – X15: temporaries
- X16 – X17 (IP0 – IP1): may be used by linker as a scratch register, other times as temporary register
- X18: platform register for platform independent code; otherwise a temporary register
- X19 – X27: saved
- X28 (SP): stack pointer
- X29 (FP): frame pointer
- X30 (LR): link register (return address)
- XZR (register 31): the constant value 0
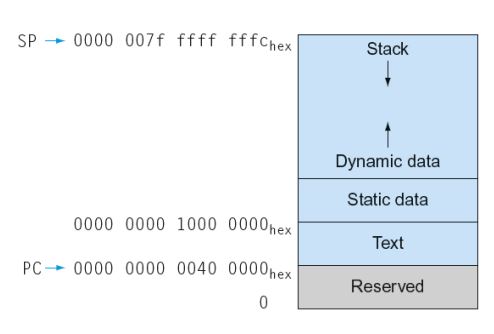
Memory Layout
- Text: program code
- Static data: global variables
- e.g., static variables in C, constant arrays and strings
- Dynamic data: heap
- E.g., malloc in C, new in Java
- Stack: automatic storage
LEGv8 Addressing Summary
LEGv8 Encoding Summary
Synchronization
- Two processors sharing an area of memory
- P1 writes, then P2 reads
- Data race if P1 and P2 don’t synchronize
- Result depends on order of accesses
- Hardware support required
- Atomic read/write memory operation
- No other access to the location allowed between the read and write
- Could be a single instruction
- E.g., atomic swap of register ↔ memory
- Or an atomic pair of instructions
Translation and Startup
![]()
Loading a Program
Load from image file on disk into memory
- Read header to determine segment sizes
- Create virtual address space
- Copy text and initialized data into memory
- Or set page table entries so they can be faulted in
- Set up arguments on stack
- Initialize registers (including SP, FP)
- Jump to startup routine
- Copies arguments to X0, … and calls main
- When main returns, do exit syscall
Dynamic Linking
- Only link/load library procedure when it is called
- Requires procedure code to be relocatable
- Avoids image bloat caused by static linking of all (transitively) referenced libraries
- Automatically picks up new library versions
Lessons Learnt
- Instruction count and CPI are not good performance indicators in isolation
- Compiler optimizations are sensitive to the algorithm
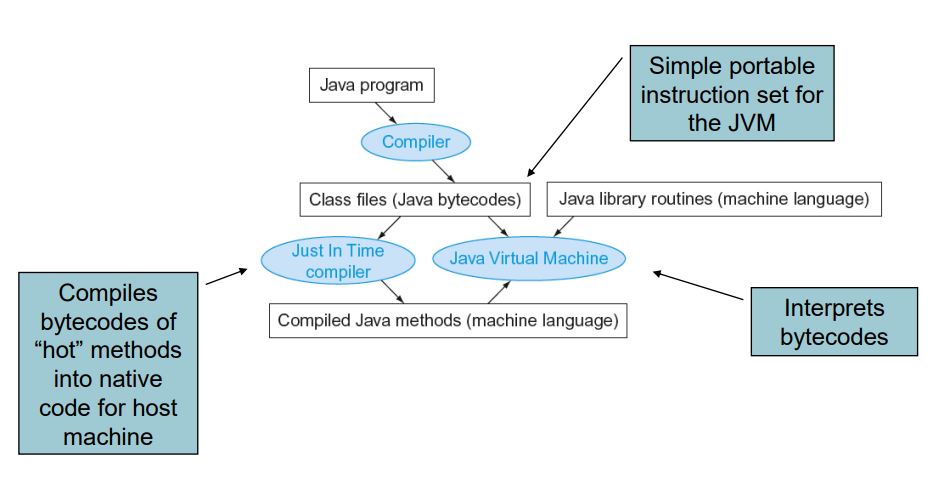
- Java/JIT compiled code is significantly faster than JVM interpreted
- Comparable to optimized C in some cases
- Nothing can fix a dumb algorithm!
Fallacies
- Powerful instruction -> higher performance
- Fewer instructions required
- But complex instructions are hard to implement
- May slow down all instructions, including simple ones
- Compilers are good at making fast code from simple instructions
- Use assembly code for high performance
- But modern compilers are better at dealing with modern processors
- More lines of code -> more errors and less productivity
- Backward compatibility -> instruction set doesn’t change
- But they do accrete more instructions
Pitfalls
- Sequential words are not at sequential addresses
- Increment by 4, not by 1!
- Keeping a pointer to an automatic variable after procedure returns
- e.g., passing pointer back via an argument
- Pointer becomes invalid when stack popped
Chapter 4 — The Processor
Logic Design Basics
- Information encoded in binary
- Low voltage = 0, High voltage = 1
- One wire per bit
- Multi-bit data encoded on multi-wire buses
- Combinational element
- Operate on data
- Output is a function of input
- AND-gate
- Multiplexer
- Adder
- Arithmetic/Logic Unit
- State (sequential) elements
- Store information
- Register: stores data in a circuit
- Uses a clock signal to determine when to update the stored value
- Edge-triggered: update when Clk changes from 0 to 1
- Register with write control
- Only updates on clock edge when write control input is 1
- Used when stored value is required later
Clocking Methodology
- Combinational logic transforms data during clock cycles
- Between clock edges
- Input from state elements, output to state element
- Longest delay determines clock period
Full Datapath
control signals derived from instruction
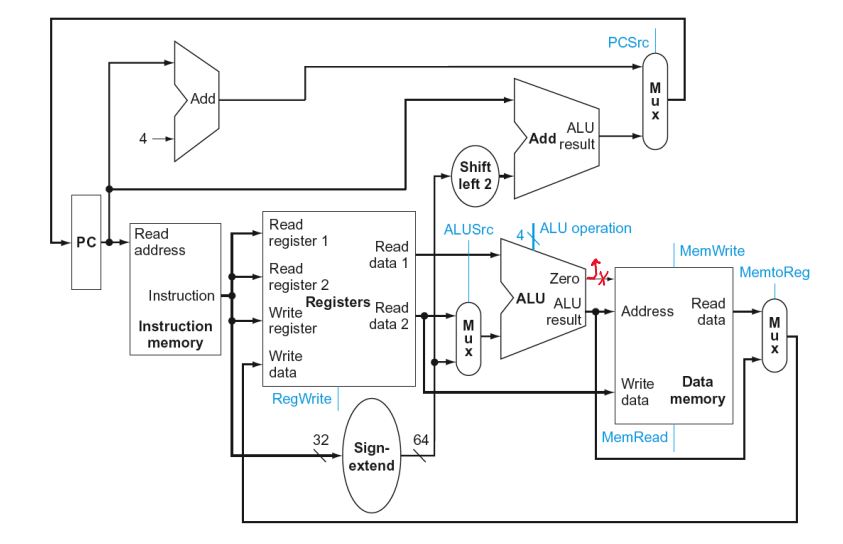
Datapath With Control
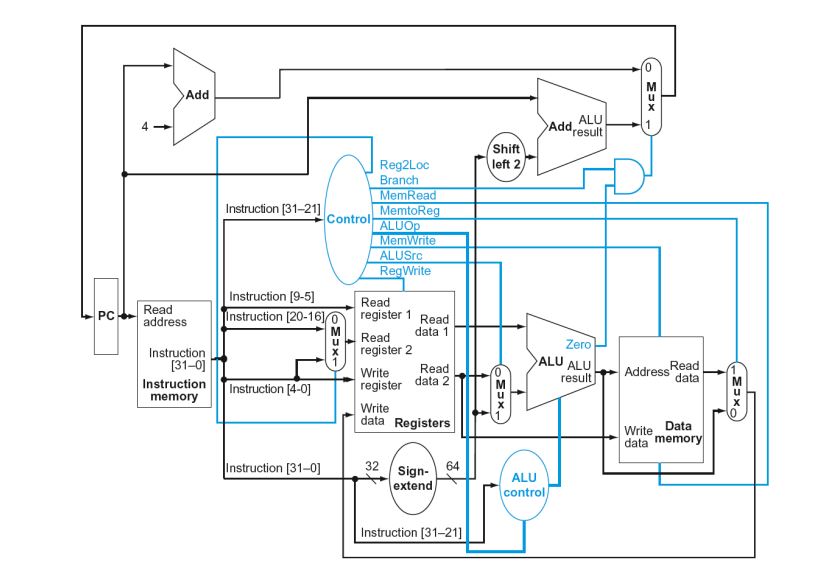
R-Type Instruction
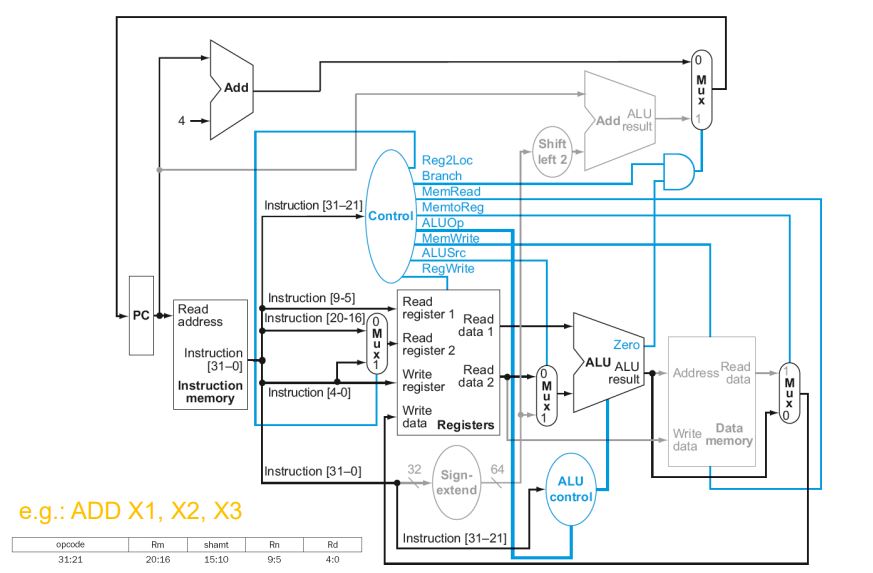
Load Instruction
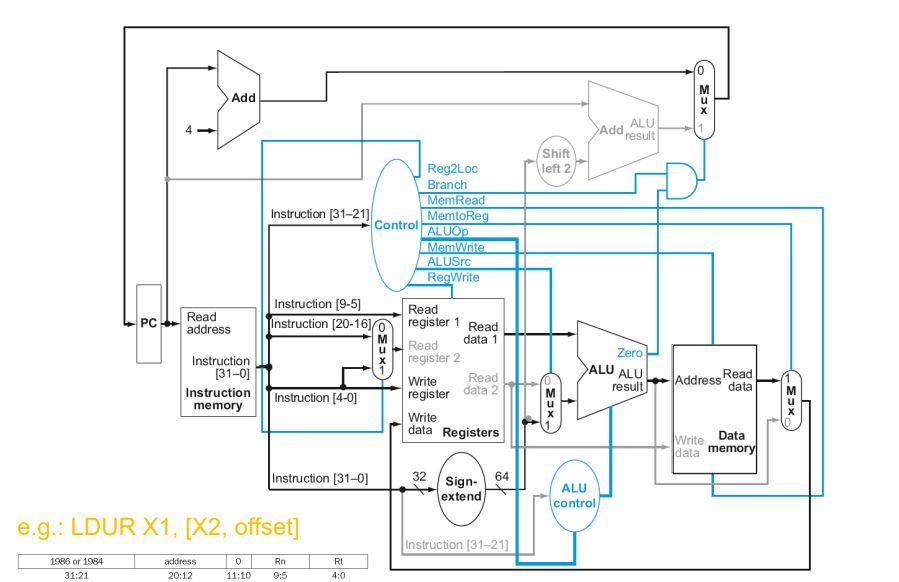
CBZ Instruction
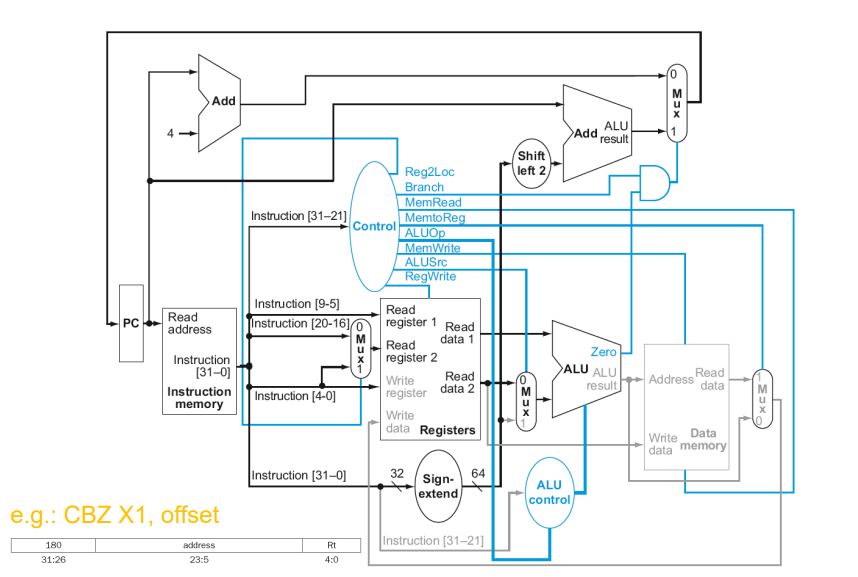
Datapath With B Added
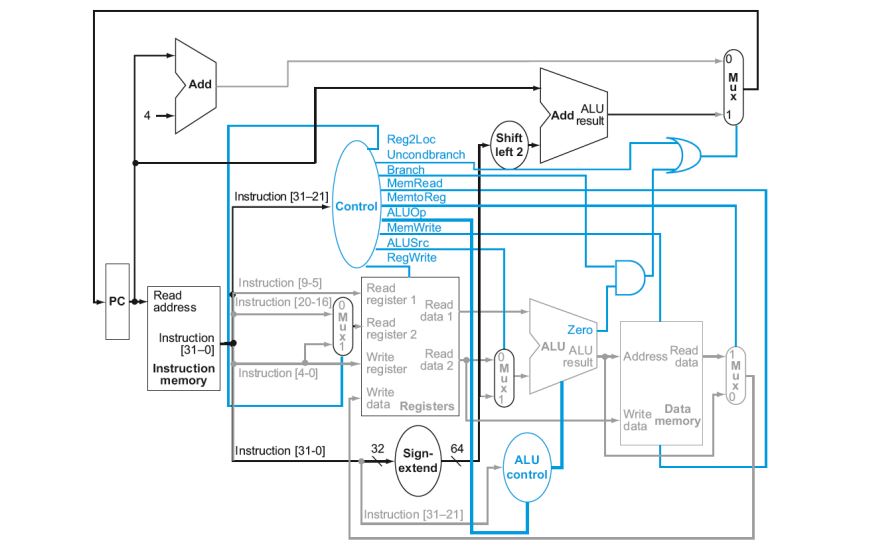
Single Cycle Performance Issues
- Longest delay determines clock period
- Critical path: load instruction
- Instruction memory → register file → ALU → data memory → register file
- Not feasible to vary period for different instructions
- Violates design principle
- Making the common case fast
- We will improve performance by pipelining
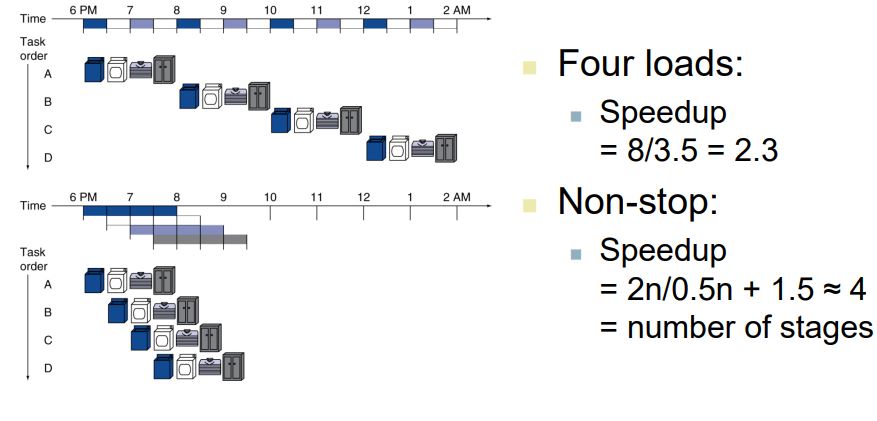
Pipelining Analogy
- Pipelined laundry: overlapping execution
- Parallelism improves performance
LEGv8 Pipeline
- Five stages, one step per stage
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
Pipeline Performance

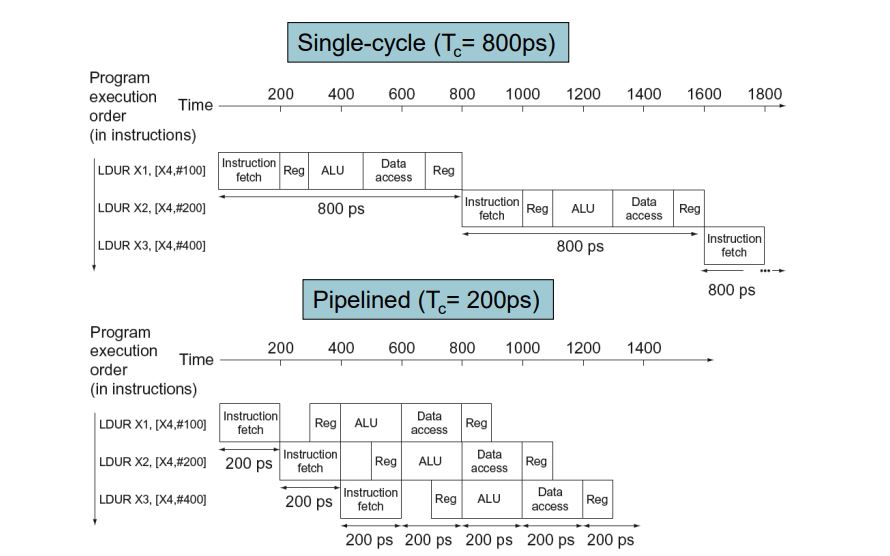
Pipeline Speedup
- If all stages take the same time (balanced)
- Time between instructions(pipelined) = Time between instructions(nonpipelined) / Number of stages
- If not balanced, speedup is less
- Speedup due to increased throughput
- Latency (time for each instruction) does not decrease
Pipelining and ISA Design
- LEGv8 ISA designed for pipelining
- All instructions are 32-bits
- Easier to fetch and decode in one cycle
- c.f. x86: 1- to 17-byte instructions
- Few and regular instruction formats
- Can decode and read registers in one step
- Load/store addressing
- Can calculate address in 3rd stage, access memory in 4th stage
- Alignment of memory operands
- Memory access takes only one cycle
- registers & stack
- All instructions are 32-bits
Hazards
Situations that prevent starting the next instruction in the next cycle
Structure hazards
- A required resource is busy
- Conflict for use of a resource
- In LEGv8 pipeline with a single memory
- Load/store requires data access
- Instruction fetch would have to stall for that cycle
- Would cause a pipeline “bubble”
- Hence, pipelined datapaths require separate instruction/data memories
- Or separate instruction/data caches
Data hazard
Need to wait for previous instruction to complete its data read/write
An instruction depends on completion of data access by a previous instruction
ADD X19, X0, X1
SUB X2, X19, X3
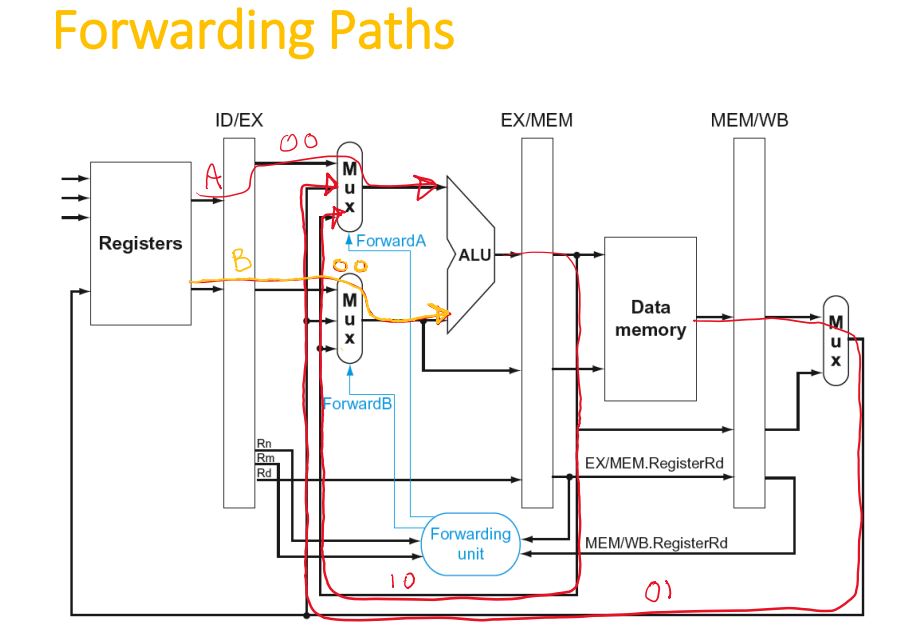
Forwarding (aka Bypassing)
- Use result when it is computed
- Don’t wait for it to be stored in a register
- Requires extra connections in the datapath
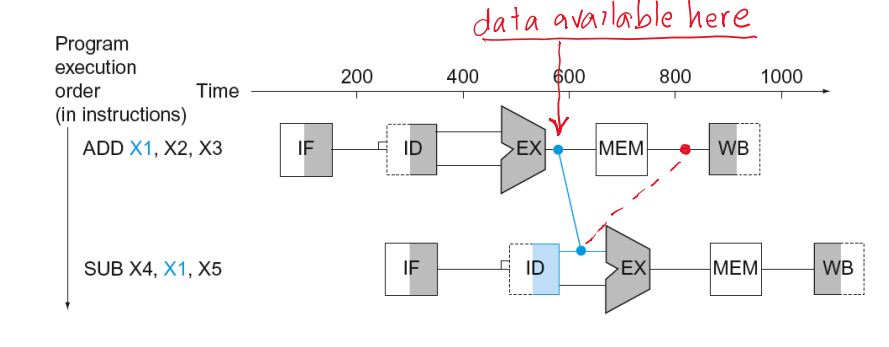
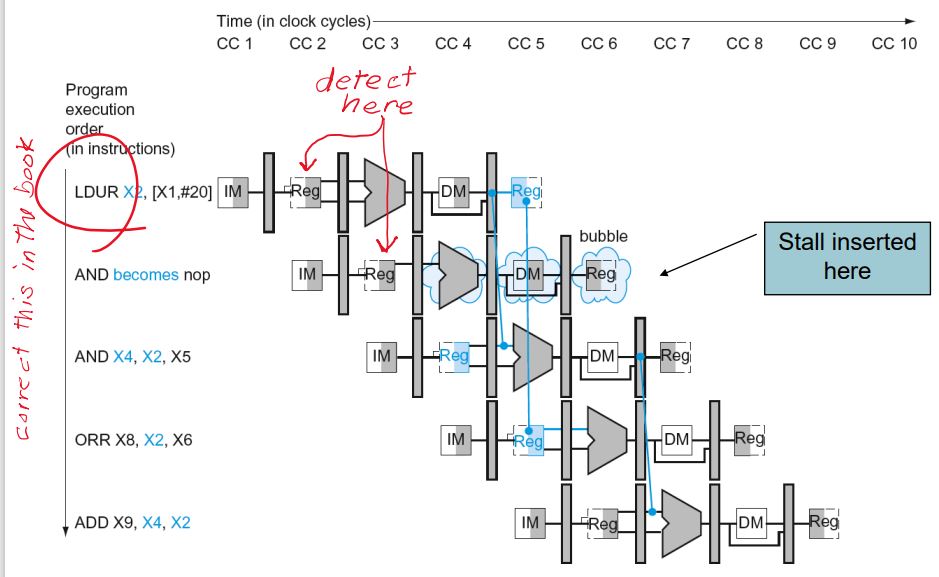
Load-Use Data Hazard
- Can’t always avoid stalls by forwarding
- If value not computed when needed
- Can’t forward backward in time!
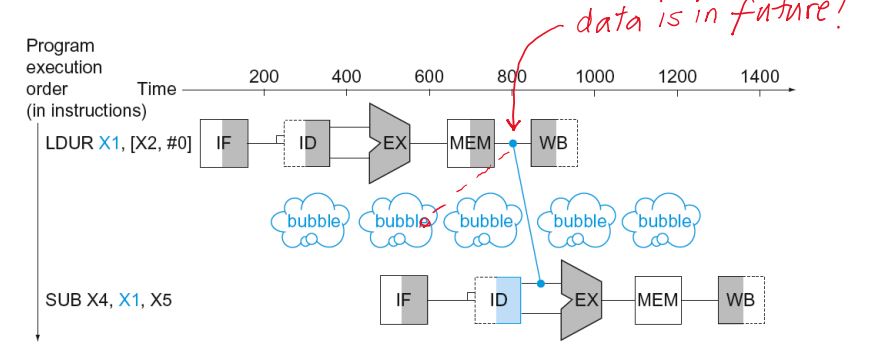
- Code Scheduling to Avoid Stalls
- Reorder code to avoid use of load result in the next instruction
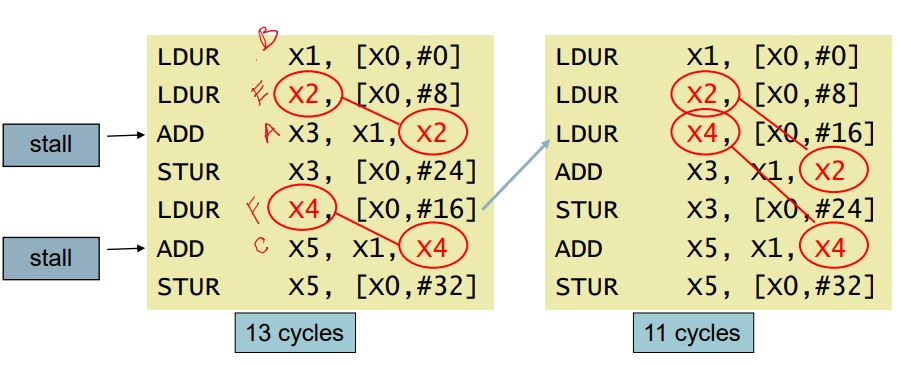
- Can’t always avoid stalls by forwarding
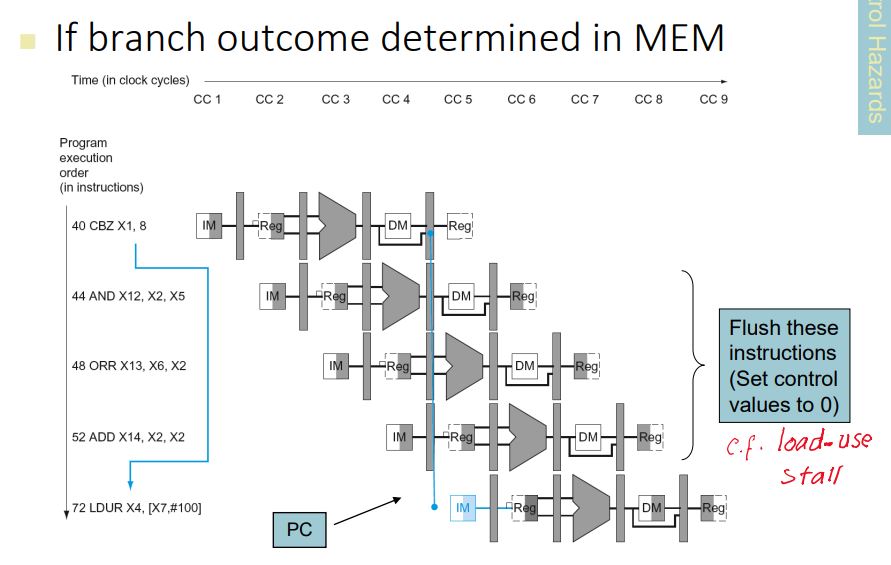
Control hazard
- Deciding on control action depends on previous instruction
- Branch determines flow of control
- Fetching next instruction depends on branch outcome
- Pipeline can’t always fetch correct instruction
- Still working on ID stage of branch
- In LEGv8 pipeline
- Need to compare registers and compute target early in the pipeline
- Add hardware to do it in ID stage
- Stall on Branch
- Wait until branch outcome determined before fetching next instruction
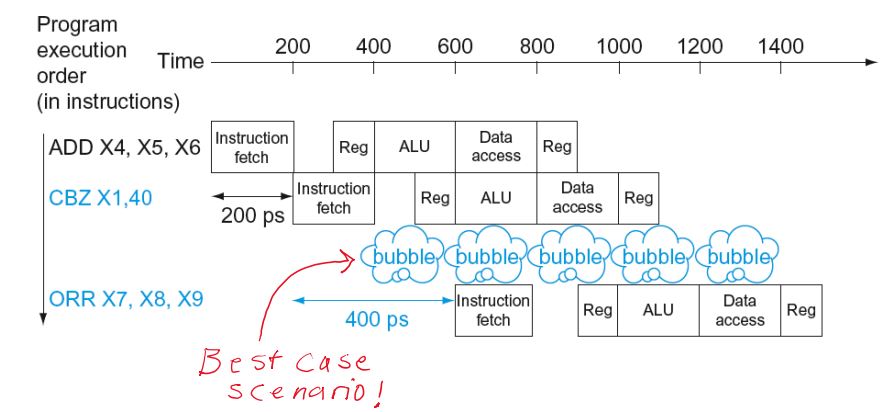
Branch Prediction
- Longer pipelines can’t readily determine branch outcome early
- Stall penalty becomes unacceptable
- Predict outcome of branch
- Only stall if prediction is wrong
- In LEGv8 pipeline
- Can predict branches not taken
- Fetch instruction after branch, with no delay
More-Realistic Branch Prediction
Static branch prediction
Based on typical branch behavior
Example: loop and if-statement branches
Predict backward branches taken
do loop
Predict forward branches not taken
for loop
Dynamic branch prediction
- Hardware measures actual branch behavior
- e.g., record recent history of each branch
- Assume future behavior will continue the trend
- When wrong, stall while re-fetching, and update history
- Hardware measures actual branch behavior
Pipeline Summary
- Pipelining improves performance by increasing instruction throughput
- Executes multiple instructions in parallel
- Each instruction has the same latency
- Subject to hazards
- Structure, data, control
- Instruction set design affects complexity of pipeline implementation
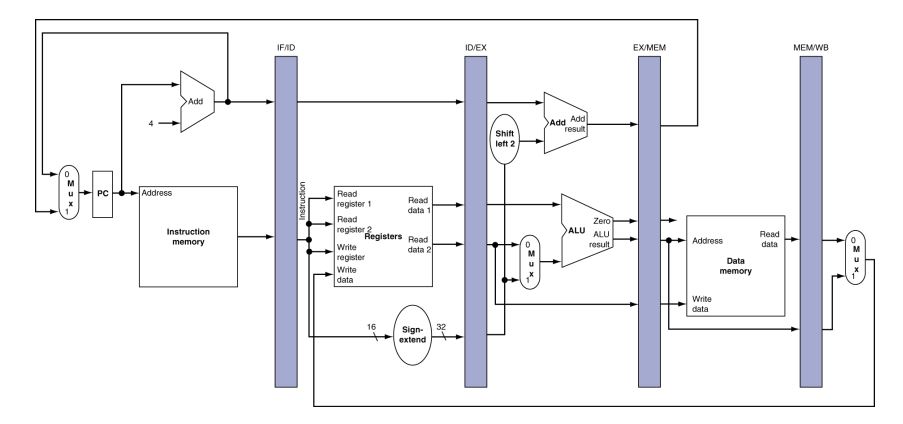
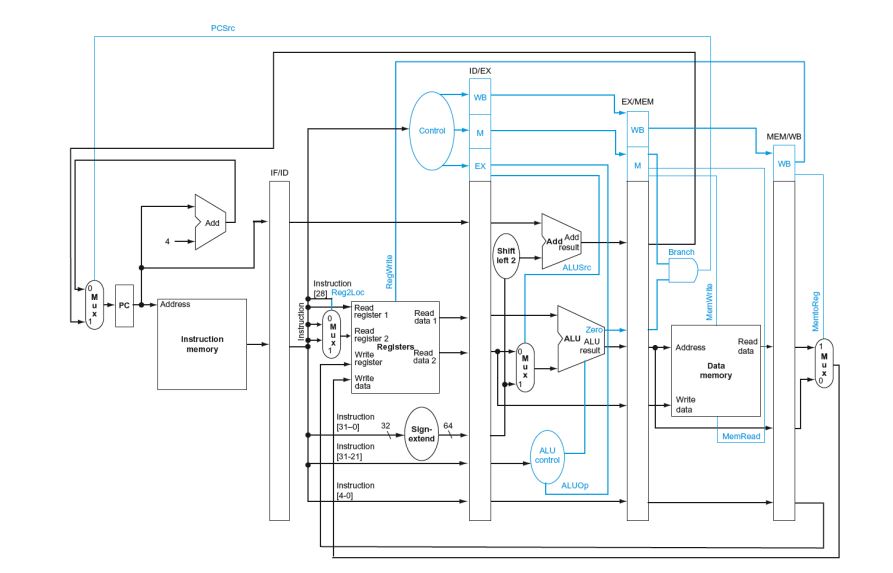
LEGv8 Pipelined Datapath
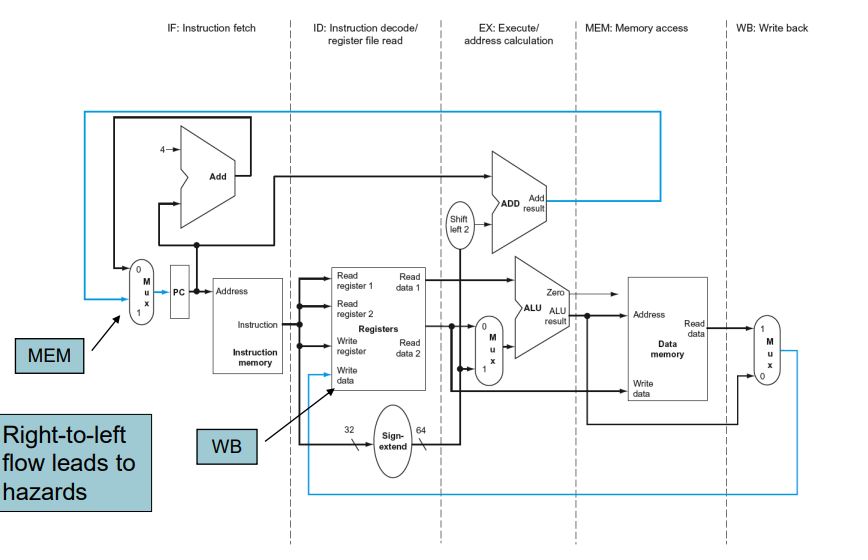
Pipeline registers
Need registers between stages
- To hold information produced in previous cycle
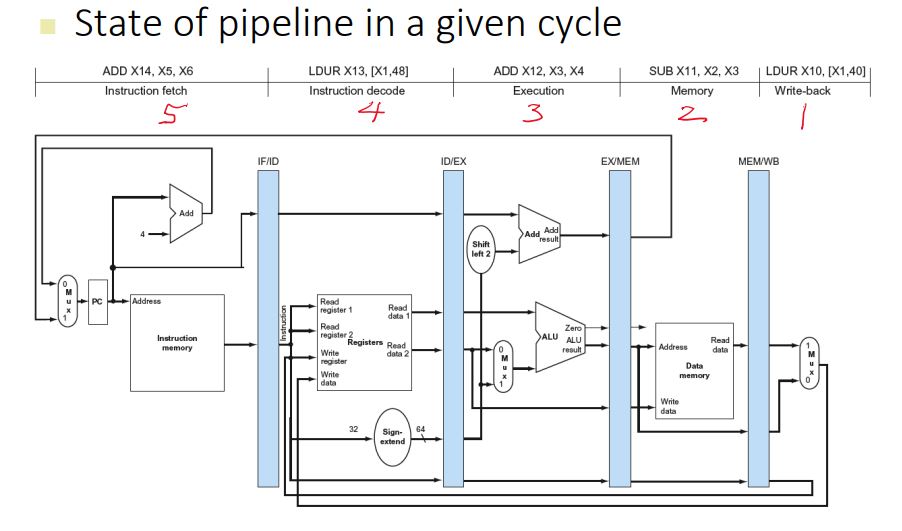
Multi-Cycle Pipeline Diagram
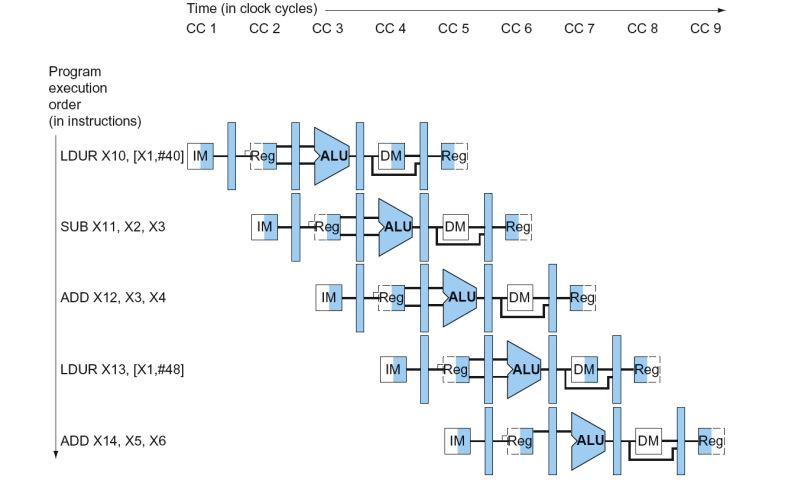
Single-Cycle Pipeline Diagram
Pipelined Control
Forwarding and Hazard Detection
Detecting the Need to Forward



- Hazard in ALU
- Load-use hazard
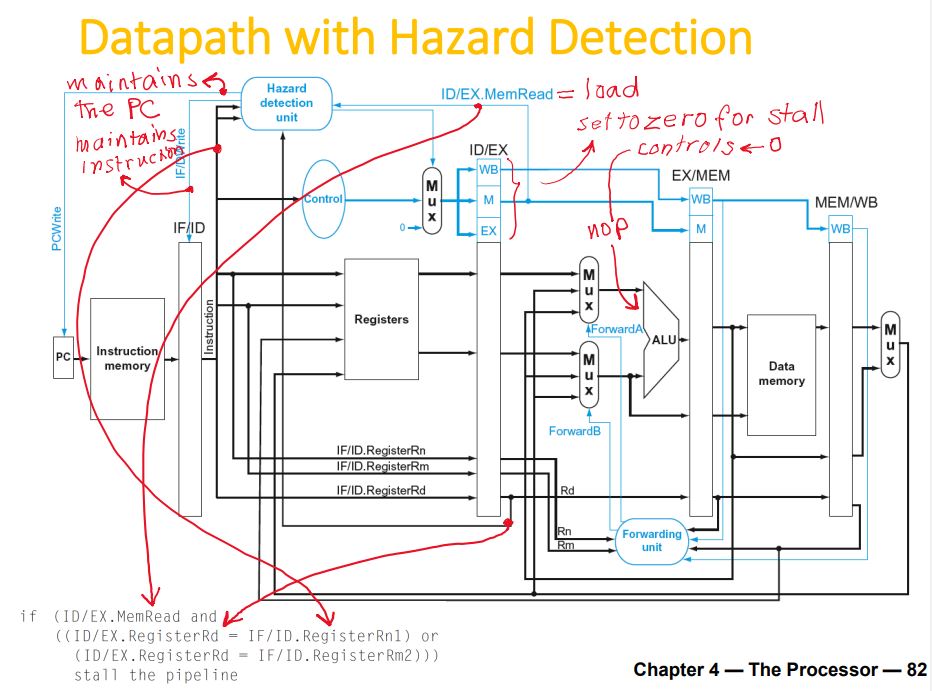
- Branch hazard
Stalls and Performance
- Stalls reduce performance
- But are required to get correct results
- Compiler can arrange code to avoid hazards and stalls
- Requires knowledge of the pipeline structure
Dynamic Branch Prediction
- In deeper and superscalar pipelines, branch penalty is more significant
- Use dynamic prediction
- Branch prediction buffer (aka branch history table)
- Indexed by recent branch instruction addresses
- Stores outcome (taken/not taken)
- To execute a branch
- Check table, expect the same outcome
- Start fetching from fall-through or target
- If wrong, flush pipeline and flip prediction
- 1-Bit Predictor: Shortcoming
- Inner loop branches mispredicted twice!
- 2-Bit Predictor
- Only change prediction on two successive mispredictions
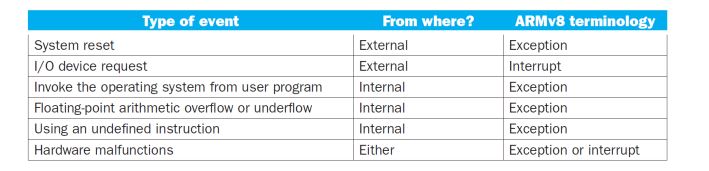
Exceptions and Interrupts
- “Unexpected” events requiring change in flow of control
- Different ISAs use the terms differently
- Exception
- Arises within the CPU
- e.g., undefined opcode, overflow, syscall, …
- Arises within the CPU
- Interrupt
- From an external I/O controller
- Dealing with them without sacrificing performance is hard
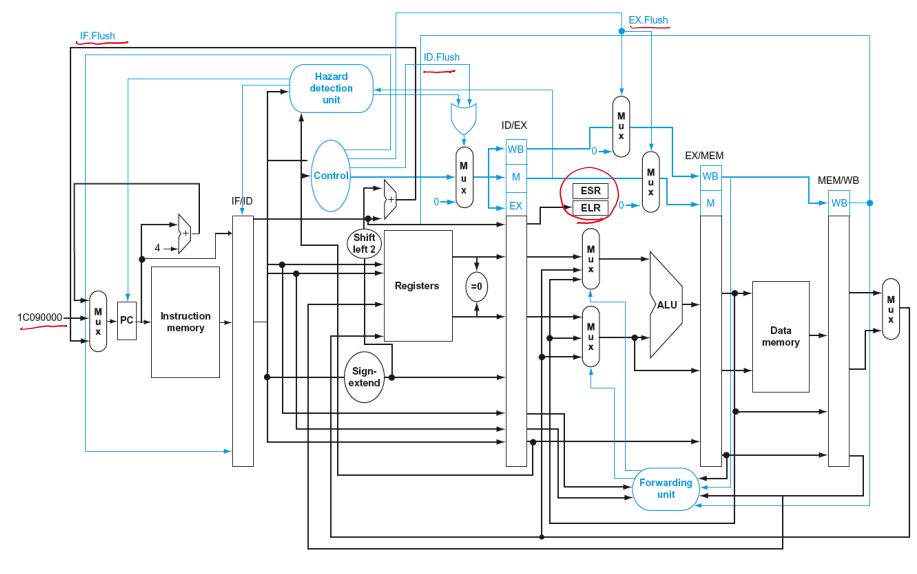
Handling Exceptions
Save PC of offending (or interrupted) instruction =EPC
- In LEGv8: Exception Link Register (ELR)
Save indication of the problem
- In LEGv8: Exception Syndrome Rregister (ESR)
- We’ll assume 1-bit
- 0 for undefined opcode, 1 for overflow
Exception Properties
- Restartable exceptions
- Pipeline can flush the instruction
- Handler executes, then returns to the instruction
- Refetched and executed from scratch
- PC saved in ELR register
- Identifies causing instruction
- Actually PC + 4 is saved
- Actually PC + 4 is saved
Instruction-Level Parallelism (ILP)
- Pipelining: multiple instructions in parallel
- To increase ILP
- Deeper pipeline
- Less work per stage -> shorter clock cycle
- Multiple issue
- Replicate pipeline stages -> multiple pipelines
- Start multiple instructions per clock cycle
- CPI < 1, so use Instructions Per Cycle (IPC)
- E.g., 4GHz 4-way multiple-issue
- 16 BIPS, peak CPI = 0.25, peak IPC = 4
- But dependencies reduce this in practice
- Deeper pipeline
Multiple Issue
- Static multiple issue (compile time)
- Compiler groups instructions to be issued together
- Packages them into “issue slots”
- Compiler detects and avoids hazards
- Dynamic multiple issue (run time)
- CPU examines instruction stream and chooses instructions to issue each cycle
- Compiler can help by reordering instructions
- CPU resolves hazards using advanced techniques at runtime
Speculation
- “Guess” what to do with an instruction
- Start the guessed operation as soon as possible
- Check whether guess was right
- If so, complete the operation
- If not, roll-back and do the right thing
- Common to static and dynamic multiple issue
- Examples
- Speculate on branch outcome
- Roll back if path taken is different
- Speculate on load
- Roll back if location is updated
- Speculate on branch outcome
Loop Unrolling
- Replicate loop body to expose more parallelism
- Reduces loop-control overhead
- Use different registers per replication
- Called “register renaming”
- Avoid loop-carried “anti-dependencies”
- Store followed by a load of the same register
- Aka “name dependence”
- Reuse of a register name
Does Multiple Issue Work?
- Yes, but not as much as we’d like
- Programs have real dependencies that limit ILP
- Some dependencies are hard to eliminate
- e.g., pointer aliasing
- Some parallelism is hard to expose
- Limited window size during instruction issue
- Memory delays and limited bandwidth
- Hard to keep pipelines full
- Speculation can help if done well
Fallacies
- Pipelining is easy (!)
- The basic idea is easy
- The devil is in the details
- e.g., detecting data hazards
- Pipelining is independent of technology
- So why haven’t we always done pipelining?
- More transistors make more advanced techniques feasible
- Pipeline-related ISA design needs to take account of technology trends
- e.g., predicated instructions
Pitfalls
- Poor ISA design can make pipelining harder
- e.g., complex instruction sets (VAX, IA-32)
- Significant overhead to make pipelining work
- IA-32 micro-op approach
- e.g., complex addressing modes
- Register update side effects, memory indirection
- e.g., delayed branches
- Advanced pipelines have long delay slots
- e.g., complex instruction sets (VAX, IA-32)
Concluding Remarks
- ISA influences design of datapath and control
- Datapath and control influence design of ISA
- Pipelining improves instruction throughput using parallelism
- More instructions completed per second
- Latency for each instruction not reduced
- Hazards: structural, data, control
- Multiple issue and dynamic scheduling (ILP)
- Dependencies limit achievable parallelism
- Complexity leads to the power wall
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
Principle of Locality
- Programs access a small portion of their address space at any time
- Temporal locality
- Items accessed recently are likely to be accessed again soon
- e.g., instructions in a loop, induction variables
- Spatial locality
- Items near those accessed recently are likely to be accessed soon
- E.g., sequential instruction access, array data
Taking Advantage of Locality
- Memory hierarchy
- Store everything on disk
- Copy recently accessed (and nearby) items from disk to smaller DRAM memory
- Main memory
- Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory
- Cache memory attached to CPU
Cache Block Size Considerations
- Larger blocks should reduce miss rate
- Due to spatial locality
- But in a fixed-sized cache
- Larger blocks -> fewer of them
- More competition -> increased miss rate
- Larger blocks -> pollution
- Partially used before being replaced
- Larger blocks -> fewer of them
- Larger miss penalty
- Can override benefit of reduced miss rate
- Early restart and critical-word-first can help
- early restart: don’t wait for everything to load
- critical-word-first: bring in the required data first
Cache Misses
- On cache hit, CPU proceeds normally
- On cache miss
- Stall the CPU pipeline
- Fetch block from next level of hierarchy
- Instruction cache miss
- Restart instruction fetch (PC - 4)
- Data cache miss
- Complete data access
On data-write hit
- Write-Through
- also update memory
- But makes writes take longer
- Solution: write buffer
- Holds data waiting to be written to memory
- CPU continues immediately
- Only stalls on write if write buffer is already full
- Write-Back
- Alternative: On data-write hit, just update the block in cache
- Keep track of whether each block is dirty
- When a dirty block is replaced
- Write it back to memory
- Can use a write buffer to allow replacing block to be read first
- Alternative: On data-write hit, just update the block in cache
Performance Summary
- When CPU performance increased
- Miss penalty becomes more significant
- Decreasing base CPI
- Greater proportion of time spent on memory stalls
- Increasing clock rate
- Memory stalls account for more CPU cycles
- Can’t neglect cache behavior when evaluating system performance
Set Associative Cache
- n-way set associative
- Each set contains n entries
- Block number determines which set
- (Block number) modulo (#Sets in cache)
- Search all entries in a given set at once
- n comparators (less expensive)
- Replacement Policy
- Prefer non-valid entry, if there is one
- Otherwise, choose among entries in the set
- Least-recently used (LRU)
- Choose the one unused for the longest time
- Random
- Least-recently used (LRU)
Multilevel Caches
- Primary cache attached to CPU
- Focus on minimal hit time
- Level-2 cache services misses from primary cache
- Focus on low miss rate to avoid main memory access
- Hit time has less overall impact
- Main memory services L-2 cache misses
- Some high-end systems include L-3 cache
Dependability Measures
- Reliability: mean time to failure (MTTF)
- Service interruption: mean time to repair (MTTR)
- Availability = MTTF / (MTTF + MTTR)
- Improving Availability
- Increase MTTF: fault avoidance, fault tolerance, fault forecasting
- Reduce MTTR: improved tools and processes for diagnosis and repair
The Hamming SEC Code
- Hamming distance
- Number of bits that are different between two bit patterns, e.g. 2 in 011011 and 001111
- Code with minimum distance = 2 provides single bit error detection
- E.g. parity code
- Minimum distance = 3 provides single error correction, 2 bit error detection
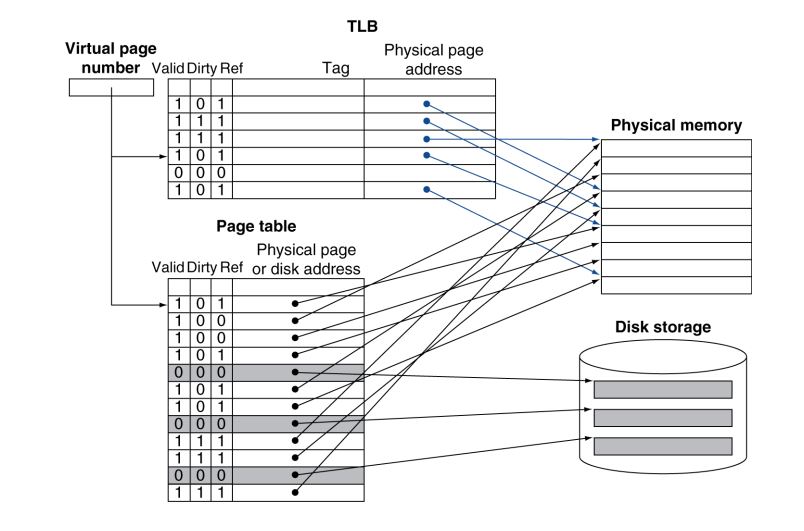
Virtual Memory
Use main memory as a “cache” for secondary (disk) storage
- Managed jointly by CPU hardware and the operating system (OS)
Programs share main memory
- Each gets a private virtual address space holding its frequently used code and data
- Protected from other programs
CPU and OS translate virtual addresses to physical addresses
- VM “block” is called a page
- VM translation “miss” is called a page fault
PTE: Page Table Entry
TLB: Translation Look-aside Buffer

Pitfalls
- Byte vs. word addressing
- Example: 32-byte direct-mapped cache, 4-byte blocks
- Byte 36 maps to block 1
- Word 36 maps to block 4
- Example: 32-byte direct-mapped cache, 4-byte blocks
- Ignoring memory system effects when writing or generating code
- Example: iterating over rows vs. columns of arrays
- Large strides result in poor locality
- In multiprocessor with shared L2 or L3 cache
- Less associativity than cores results in conflict misses
- More cores -> need to increase associativity
- Using AMAT to evaluate performance of out-of-order processors
- Ignores effect of non-blocked accesses
- Instead, evaluate performance by simulation
- Extending address range using segments
- E.g., Intel 80286
- But a segment is not always big enough
- Makes address arithmetic complicated
- Implementing a VMM on an ISA not designed for virtualization
- E.g., non-privileged instructions accessing hardware resources
- Either extend ISA, or require guest OS not to use problematic instructions
Concluding Remarks
- Fast memories are small, large memories are slow
- We really want fast, large memories
- Caching gives this illusion
- Principle of locality
- Programs use a small part of their memory space frequently
- Memory hierarchy
- L1 cache <-> L2 cache <-> … <-> DRAM memory <-> disk
- Memory system design is critical for multiprocessors
Chapter 6 — Parallel Processors from Client to Cloud
GPU Architectures
- Processing is highly data-parallel
- GPUs are highly multithreaded
- Use thread switching to hide memory latency
- Less reliance on multi-level caches
- Graphics memory is wide and high-bandwidth
- Trend toward general purpose GPUs
- Heterogeneous CPU/GPU systems
- CPU for sequential code, GPU for parallel code
- Programming languages/APIs
- DirectX, OpenGL
- C for Graphics (Cg), High Level Shader Language (HLSL)
- Compute Unified Device Architecture (CUDA
Concluding Remarks
- Goal: higher performance by using multiple processors
- Difficulties
- SaaS importance is growing and clusters are a good match
- Performance per dollar and performance per Joule drive both mobile and WSC
- SIMD and vector operations match multimedia applications and are easy to program