COEN317 Final Review
Global Time and Global State
- Asynchronous distributed systems consist of several processes without common memory which communicate via messages with unpredictable transmission delays
- Global time & global state are hard to realize in distributed systems
- Processes are distributed geographically
- Rate of event occurrence can be high (unpredictable)
- Event execution times can be small
- We can only approximate the global view
- Simulate a global time – Logical Clocks
- Simulate a global state – Global Snapshots
Simulating global time
An accurate notion of global time is difficult to achieve in distributed systems.
- We often derive “causality” from loosely synchronized clocks
Clocks in a distributed system drift
- Relative to each other
- Relative to a real world clock
- Determination of this real world clock itself may be an issue
- Clock Skew versus Drift
- Clock Skew = Relative Difference in clock values of two processes
- Clock Drift = Relative Difference in clock frequencies (rates) of two processes
Clock synchronization is needed to simulate global time
- Correctness – consistency, fairness
Physical Clocks vs. Logical clocks
- Physical clocks - must not deviate from the real-time by more than a certain amount.
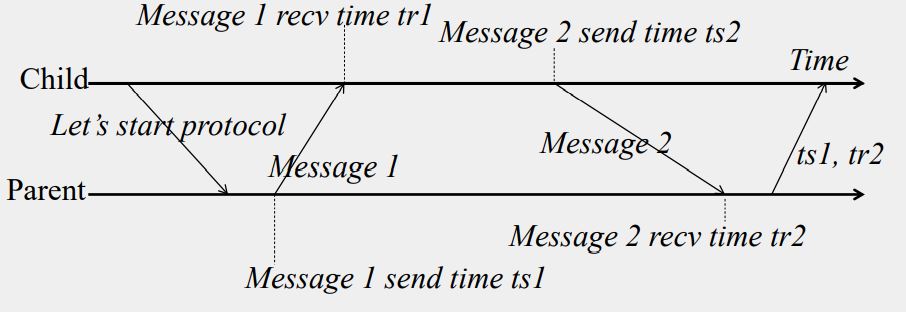
Cristian’s (Time Server) Algorithm
Uses a time server to synchronize clocks
- Time server keeps the reference time (say UTC)
- A client asks the time server for time, the server responds with its current time, and the client uses the received value T to set its clock
But network round-trip time introduces errors…
Let RTT = response-received-time – request-sent-time (measurable at client),
If we know
- (a) min1 = minimum P -> S latency
- (b) min2 = minimum S -> P latency
- (c) that the server timestamped the message at the last possible instant before sending it back
Then, the actual time could be between [T+min2,T+RTT— min1]
P sets its time to halfway through this interval
- To: t + (RTT+min2-min1)/2
Error is at most (RTT-min2-min1)/2
- Bounded!
Berkeley UNIX algorithm
- One daemon without UTC
- Periodically, this daemon polls and asks all the machines for their time
- The machines respond.
- The daemon computes an average time and then broadcasts this average time.
Decentralized Averaging Algorithm
- Each machine has a daemon without UTC
- Periodically, at fixed agreed-upon times, each machine broadcasts its local time.
- Each of them calculates the average time by averaging all the received local times.
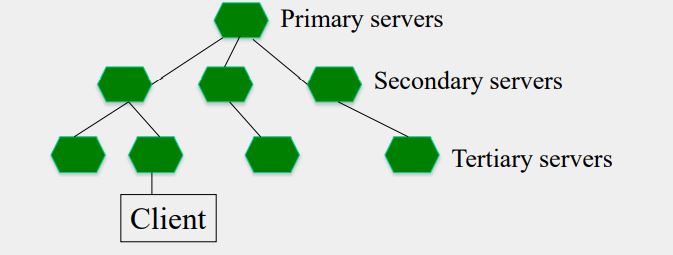
Network Time Protocol (NTP)
- Most widely used physical clock synchronization protocol on the Internet
- Hierarchical tree of time servers.
- The primary server at the root synchronizes with the UTC.
- Secondary servers - backup to primary server.
- Lowest
- synchronization subnet with clients.



Event Ordering
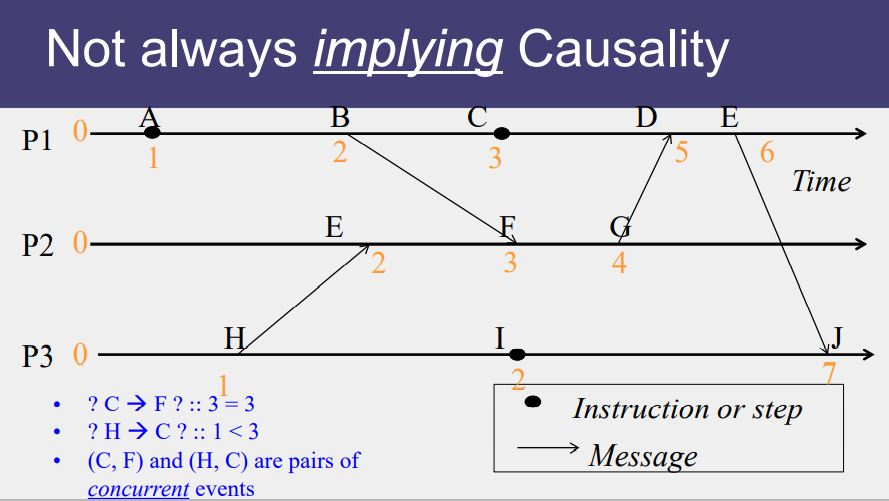
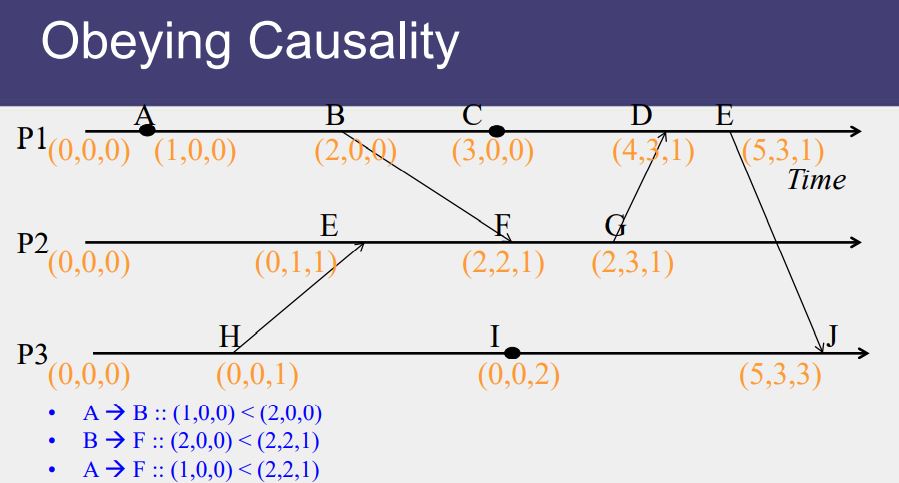
- Lamport defined the “happens before” (->) relation
- If a and b are events in the same process, and a occurs before b, then a->b.
- If a is the event of a message being sent by one process and b is the event of the message being received by another process, then a -> b.
- If X -> Y and Y-> Z then X -> Z.
- If a -> b then time (a) < time (b)
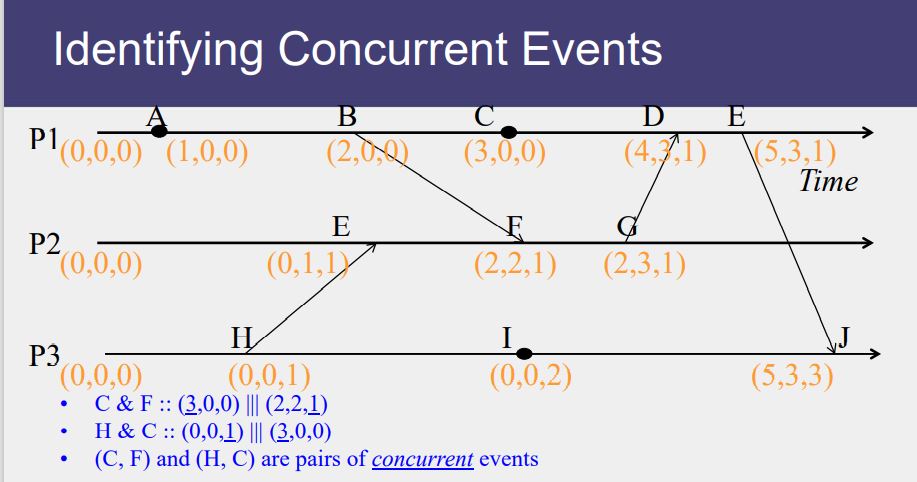
Causal Ordering
“Happens Before” also called causal ordering
Possible to draw a causality relation between 2 events if
- They happen in the same process
- There is a chain of messages between them
“Happens Before” notion is not straightforward in distributed system
No guarantees of synchronized clocks
Communication latency
Types of Logical Clocks
- Systems of logical clocks differ in their representation of logical time and also in the protocol to update the logical clocks.
- 2 kinds of logical clocks
- Lamport
- Vector
Lamport Clock
Proposed by Lamport in 1978 as an attempt to totally order events in a distributed system.
Each process uses a local counter (clock) which is an integer
initial value of counter is set to a non-negative integer or zero
A process increments its counter when a send or an instruction happens at it.
The counter is assigned to the event as its timestamp.
Each process keeps its own logical clock used to timestamp events
A send (message) event carries its timestamp
For a receive (message) event the counter is updated by
- max(local clock, message timestamp) + 1
Vector Timestamp
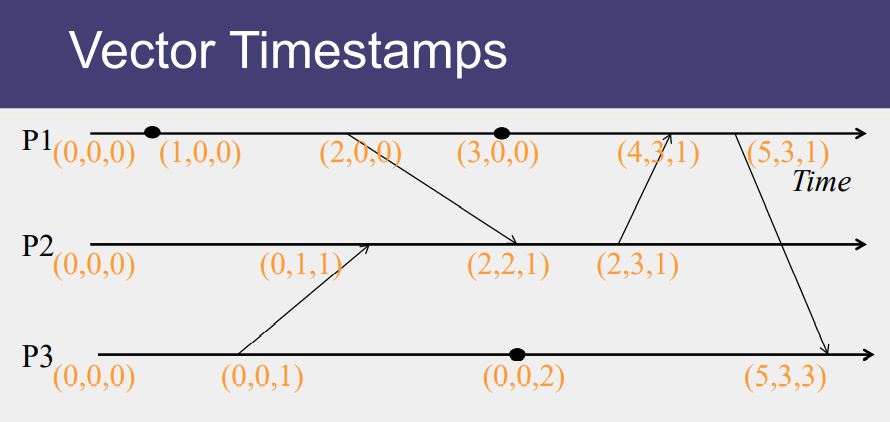
- In the system of vector clocks, the time domain is represented by a set of n-dimensional non-negative integer vectors.
- Each process has a clock Ci consisting of a vector of length n, where n is the total number of processes vt[1..n], where vt[j ] is the local logical clock of Pj and describes the logical time progress at process Pj .
- Incrementing vector clocks
- On an instruction or send event at process i, it increments only its ith element of its vector clock
- Each message carries the send-event’s vector timestamp Vmessage[1…N]
- On receiving a message at process i:
- Vi[i] = Vi[i] + 1
- Vi[j] = max(Vmessage[j], Vi[j]) for j≠ i
- Vector Clocks example


Global State
- Recording the global state of a distributed system on-the-fly is an important paradigm.
- Challenge: lack of globally shared memory, global clock and unpredictable message delays in a distributed system
- Notions of global time and global state closely related
- A process can (without freezing the whole computation) compute the best possible approximation of global state
- A global state that could have occurred
- No process in the system can decide whether the state did really occur
- Guarantee stable properties (i.e. once they become true, they remain true)
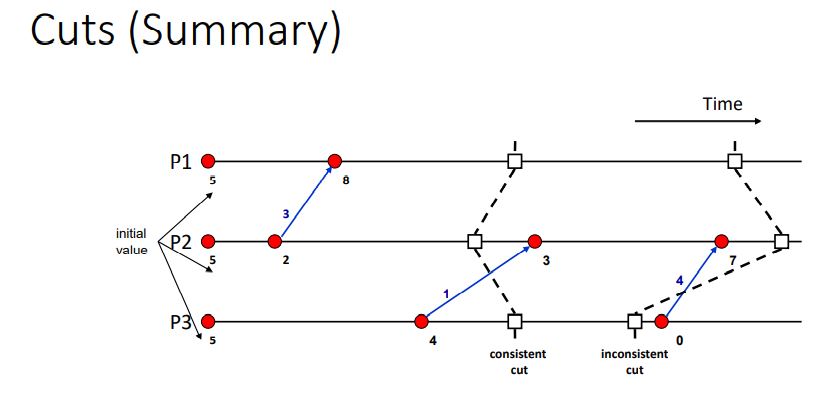
Consistent Cuts
- A cut (or time slice) is a zigzag line cutting a time diagram into 2 parts (past and future)
- Consistent Cut: a cut that obeys causality
- A cut C is a consistent cut if and only if:
- for (each pair of events e, f in the system)
- Such that event e is in the cut C, and if f->e (f happens-before e)
- Then: Event f is also in the cut C
- A cut C is a consistent cut if and only if:
System Model for Global Snapshots
- The system consists of a collection of n processes p1, p2, …, pn that are connected by channels.
- There are no globally shared memory and physical global clock and processes communicate by passing messages through communication channels.
- Cij denotes the channel from process pi to process pj and its state is denoted by Si
- The actions performed by a process are modeled as three types of events:
- Internal events,the message send event and the message receive event.
- For a message mij that is sent by process pi to process pj , let send(mij ) and rec(mij ) denote its send and receive events.
Chandy-Lamport Distributed Snapshot Algorithm
- Assumes FIFO communication in channels
- Uses a marker message to separate messages in the channels.
- After a process has recorded its snapshot, it sends a marker, along all of its outgoing channels before sending out any more messages.
- The marker separates the messages in the channel into those to be included in the snapshot from those not to be recorded in the snapshot.
- A process must record its snapshot no later than when it receives a marker on any of its incoming channels.
- The algorithm terminates after each process has received a marker on all of its incoming channels.
- All the local snapshots get disseminated to all other processes and all the processes can determine the global state



- Global Snapshot calculated by Chandy-Lamport algorithm is causally correct
Distributed Mutual Exclusion
- Mutual exclusion
- ensures that concurrent processes have serialized access to shared resources - the critical section problem
- At any point in time, only one process can be executing in its critical section
- Shared variables (semaphores) cannot be used in a distributed system
- Mutual exclusion must be based on message passing, in the context of unpredictable delays and incomplete knowledge
Approaches to Distributed Mutual Exclusion
- Central coordinator-based approach
- A centralized coordinator determines who enters the CS
- Distributed approaches to mutual exclusion
- Token based approach
- A unique token is shared among the processes. A process is allowed to enter its CS if it possesses the token.
- Mutual exclusion is ensured because the token is unique.
- Non-token based approach
- Two or more successive rounds of messages are exchanged among the processes to determine which process will enter the CS next.
- Quorum based approach
- Each process requests permission to execute the CS from a subset of processes (called a quorum).
- Any two quorums contain a common process. This common process makes sure that only one request executes the CS at any time.
- Token based approach
Requirements/Conditions
- Safety Property
- At any instant, only one process can execute the critical section.
- Liveness Property
- This property states the absence of deadlock and starvation. Two or more processess should not endlessly wait for messages which will never arrive.
- Ordering/Fairness
- Each process gets a fair chance to execute the CS which means the CS execution requests are executed in the order of their arrival (time is determined by a logical clock) in the system.
Mutual Exclusion Techniques Covered
Central Coordinator Algorithm
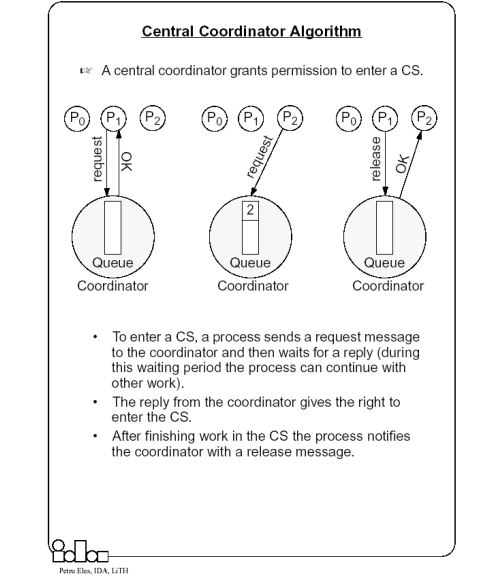
In a distributed environment it seems more natural to implement mutual exclusion, based upon distributed agreement - not on a central coordinator.
Distributed Non-token based
- Ricart-Agrawala Algorithm
- Maekawa’s Algorithm
Ricart-Agrawala Algorithm
- Uses only two types of messages – REQUEST and REPLY.
- It is assumed that all processes keep a (Lamport’s) logical clock which is updated according to the clock rules.
- Requests are ordered according to their global logical timestamps; if timestamps are equal, process identifiers are compared to order them.
- The process that requires entry to a CS multicasts the request message to all other processes competing for the same resource.
- Process is allowed to enter the CS when all processes have replied to this message.
- The request message consists of the requesting process’ timestamp (logical clock) and its identifier.
- Each process keeps its state with respect to the CS: released, requested, or held.

Analysis: Ricart-Agrawala’s Algorithm
- Safety
- Two processes Pi and Pj cannot both have access to CS
- Liveness
- Worst-case: wait for all other (N-1) processes to send Reply
- Ordering
- Requests with lower Lamport timestamps are granted earlier
Performance: Ricart-Agrawala’s Algorithm
- Bandwidth: 2*(N-1) messages per enter() operation
- Client delay: one round-trip time
- Synchronization delay: one message transmission time
Quorum-Based – Maekawa’s Algorithm
Site obtains permission only from a subset of sites to enter CS
Multicasts messages to a voting subset of processes
Each process pi is associated with a voting set vi (of processes)
- Each process belongs to its own voting set
- The intersection of any two voting sets is non-empty
- Each voting set is of size K
- Each process belongs to M other voting sets
To access a critical section, pi requests permission from all other processes in its own voting set vi
Voting set member gives permission to only one requestor at a time, and queues all other requests
Guarantees safety
May not guarantee liveness (may deadlock)
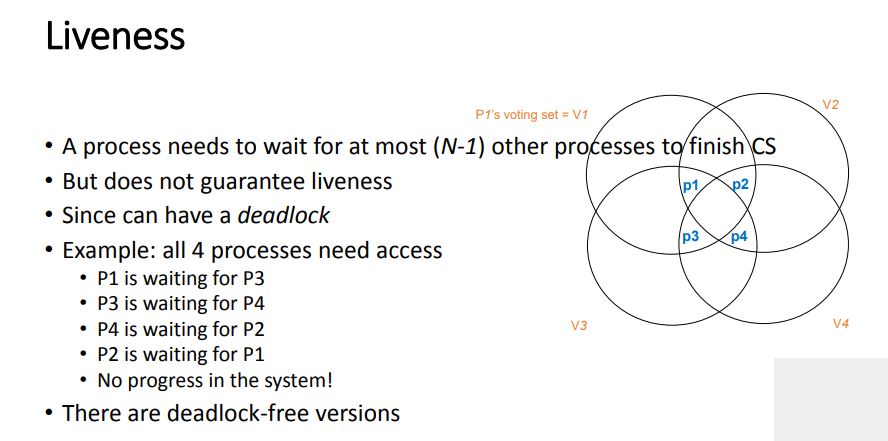
Maekawa showed that K=M=N^0.5 works best


Election Algorithms
- It doesn’t matter which process is elected.
- What is important is that one and only one process is chosen (we call this process the coordinator) and all processes agree on this decision
- Assume that each process has a unique number (identifier)
- In general, election algorithms attempt to locate the process with the highest number, among those which currently are up
- Election is typically started after a failure occurs
- The detection of a failure (e.g. the crash of the current coordinator) is normally based on time-out → a process that gets no response for a period of time suspects a failure and initiates an election process.
- An election process is typically performed in two phases:
- Select a leader with the highest priority.
- Inform all processes about the winner.
The Ring-based Algorithm
- We assume that the processes are arranged in a logical ring
- Each process knows the address of one other process, which is its neighbor in the clockwise direction
- The algorithm elects a single coordinator, which is the highest id process.
- Election is started by a process which detects the coordinator failure
- The process prepares an election message which includes its id and passed it to the successor process.
- When a process receives an election message
- It compares the identifier in the message with its own
- If the arrived identifier is greater, it forwards the received election message to its neighbor
- If the arrived identifier is smaller, it substitutes its own identifier in the election message before forwarding it.
- If the received id is that of the receiver itself → this will be the coordinator.
- The new coordinator sends an elected message through the ring

The Bully Algorithm
- A process has to know the identifier of all other processes
- (it doesn’t know, however, which one is still up); the process with the highest identifier, among those which are up, is selected.
- Any process could fail during the election procedure.
- When a process Pi detects a failure and a coordinator has to be elected
- it sends an election message to all the processes with a higher identifier and then waits for an answer message:
- If no response arrives within a time limit
- Pi becomes the coordinator (all processes with higher identifier are down)
- it broadcasts a coordinator message to all processes to let them know.
- If an answer message arrives,
- Pi knows that another process has to become the coordinator → it waits in order to receive the coordinator message.
- If this message fails to arrive within a time limit (which means that a potential coordinator crashed after sending the answer message) Pi resends the election message.
- When receiving an election message from Pi
- a process Pj replies with an answer message to Pi and
- then starts an election procedure itself( unless it has already started one) it sends an election message to all processes with higher identifier.
- Finally all processes get an answer message, except the one which becomes the coordinator.

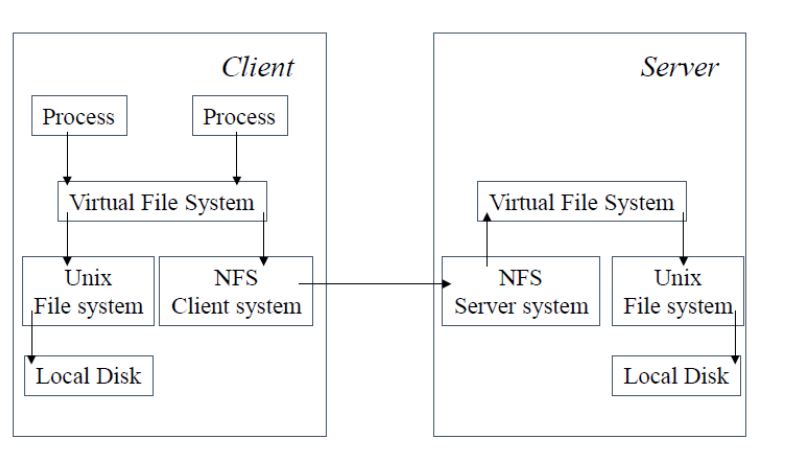
Distributed File System (DFS)
- Files are stored on a server machine
- client machine does RPCs to server to perform operations on file
- Desirable Properties from a DFS
- Transparency: client accesses DFS files as if it were accessing local files
- Same API as local files, i.e., client code doesn’t change
- Need to make location, replication, etc. invisible to client
- Support concurrent clients
- Multiple client processes reading/writing the file concurrently
- Transparency: client accesses DFS files as if it were accessing local files
- Replication: for fault-tolerance
File Sharing Semantics
- One-copy Serializability
- Updates are written to the single copy and are available immediately
- Serializability
- Transaction semantics (file locking protocols implemented - share for read, exclusive for write).
Example: Sun-NFS
Network File System
Supports heterogeneous systems
Architecture
- Server exports one or more directory trees for access by remote clients
- Clients access exported directory trees by mounting them to the client local tree
Protocols
- Mounting protocol
- Directory and file access protocol - stateless, no open-close messages, full access path on read/write
NFS Architecture
Example: Andrew File System
Designed at CMU
- Named after Andrew Carnegie and Andrew Mellon, the “C” and “M” in CMU
In use today in some clusters (especially University clusters)
Supports information sharing on a large scale
Uses a session semantics
- Entire file is copied to the local machine (Venus) from the server (Vice) when open. If file is changed, it is copied to server when closed.
- Works because in practice, most files are changed by one person
- Entire file is copied to the local machine (Venus) from the server (Vice) when open. If file is changed, it is copied to server when closed.
Replication
Enhances a service by replicating data
Increased Availability
- Of service. When servers fail or when the network is partitioned.
Fault Tolerance
- Under the fail-stop model, if up to f of f+1 servers crash, at least one is alive
Load Balancing
- One approach: Multiple server IPs can be assigned to the same name in DNS, which returns answers round-robin.
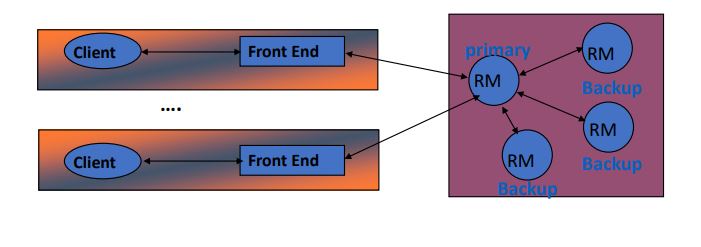
Passive Replication
uses a primary replica (master)
master: elected leader
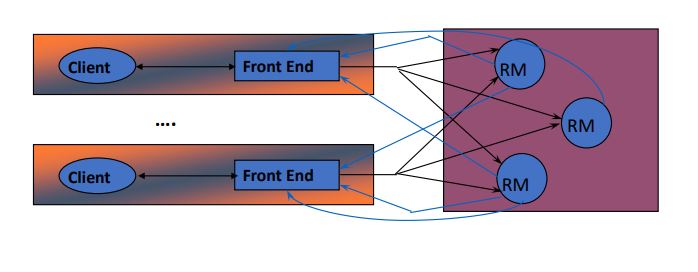
Active Replication
treats all replicas identically
multicast inside replica group
can use any flavor of multicast ordering
- FIFO ordering
- causal ordering
- total ordering
- hybrid ordering
Transactions
Sequence of Read/Write operations that act as ONE unit of execution
ACID Properties
- Atomicity
- All or nothing
- a transaction should either
- i)complete successfully, so its effects are recorded in the server objects;
- or ii) the transaction has no effect at all.
- Consistency
- if the server starts in a consistent state, the transaction ends the server in a consistent state.
- Isolation
- Each transaction must be performed without interference from other transactions
- i.e., non-final effects of a transaction must not be visible to other transactions
- Durability
- After a transaction has completed successfully, all its effects are saved in permanent storage.
- Atomicity
Serializable Schedule
- Goal: increase concurrency while maintaining correctness (ACID)
- Equivalent to some Serial execution → Correctness
- Serial Equivalency Test
serial
- An interleaving (say O) of transaction operations is serially equivalent iff (if and only if):
- Cannot distinguish end-result of real operation O from (fake) serial transaction order O’
- An interleaving (say O) of transaction operations is serially equivalent iff (if and only if):
Distributed Transactions
- Transactions distributed based on which entity hosts the object/replica
- One-phase Commit: Issues
- Server with object has no say in whether transaction commits or aborts
- If object corrupted, it just cannot commit (while other servers have committed)
- Server may crash before receiving commit message, with some updates still in memory
- Server with object has no say in whether transaction commits or aborts
- Uses 2 Phase Commit protocol for guaranteeing atomic commit (in contrast to 1 Phase Commit)
- Failures in Two-phase Commit
- To deal with server crashes
- Each server saves tentative updates into permanent storage, right before replying Yes/No in first phase. Retrievable after crash recovery
- To deal with coordinator crashes
- Coordinator logs all decisions and received/sent messages on disk
- After recovery or new election => new coordinator takes over
- To deal with Yes/No message loss,
- coordinator aborts the transaction after a timeout (pessimistic!)
- To deal with Commit or Abort message loss
- Server can poll coordinator (repeatedly)
- To deal with server crashes
- Failures in Two-phase Commit
Concurrency Control
- Optimistic Concurrency Control
- Used in Dropbox, Google apps, Wikipedia, key-value stores like Cassandra, Riak, and Amazon’s Dynamo
- Used for Read/Read-Only transaction
- Allow the transaction to execute
- If Serial Equivalency passed, then commit. Otherwise, abort
- Pessimistic Concurrency Control
- Use Locking (Mutual Exclusion)
- 2 Phase Locking protocol (2PL)
- Growing/expanding phase – Acquire locks
- Shrinking phase – release locks and no new locks can be acquired
- Strict 2PL – hold on to locks until transactions commits/aborts
Deadlocks
3 necessary conditions for a deadlock to occur
- Some objects are accessed in exclusive lock modes
- Transactions holding locks cannot be preempted
- There is a circular wait (cycle) in the Wait-for graph
Handling Deadlocks
Lock timeout:
- abort transaction if lock cannot be acquired within timeout
- Expensive; leads to wasted work
Deadlock Detection:
- keep track of Wait-for graph (e.g., via Global Snapshot algorithm), and
- find cycles in it (e.g., periodically)
- If find cycle, there’s a deadlock => Abort one or more transactions to break cycle
- Still allows deadlocks to occur
Deadlock Prevention
Set up the system so one of the necessary conditions is violated
Some objects are accessed in exclusive lock modes
Fix: Allow read-only access to objects
Transactions holding locks cannot be preempted
Fix: Allow preemption of some transactions
There is a circular wait (cycle) in the Wait-for graph
Fix: Lock all objects in the beginning; if fail any, abort transaction => No cycles in Wait-for graph
Security
- Threats
- Leakage
- Unauthorized access to service or data
- E.g., Someone knows your bank balance
- Tampering
- Unauthorized modification of service or data
- E.g., Someone modifies your bank balance
- Vandalism
- Interference with normal service, without direct gain to attacker
- E.g., Denial of Service attacks
- Leakage
- Common Attacks
- Eavesdropping
- Attacker taps into network
- Masquerading
- Attacker pretends to be someone else, i.e., identity theft
- Message tampering
- Attacker modifies messages
- Replay attack
- Attacker replays old messages
- Denial of service
- bombard a port
- Eavesdropping
- CIA properties
- Confidentiality
- Protection against disclosure to unauthorized individuals
- Addresses Leakage threat
- Integrity
- Protection against unauthorized alteration or corruption
- Addresses Tampering threat
- Availability
- Service/data is always readable/writable
- Addresses Vandalism threat
- Confidentiality
- Policy vs Mechanism
- Many scientists (e.g., Hansen) have argued for a separation of policy vs. mechanism
- A security policy indicates what a secure system accomplishes
- A security mechanism indicates how these goals are accomplished
- E.g.,
- Policy: in a file system, only authorized individuals allowed to access files (i.e., CIA properties)
- Mechanism: Encryption, capabilities, etc.
- Mechanisms: Golden A’s
- Authentication
- Is a user (communicating over the network) claiming to be Alice, really Alice?
- Authorization
- Yes, the user is Alice, but is she allowed to perform her requested operation on this object?
- Auditing
- How did Eve manage to attack the system and breach defenses? Usually done by continuously logging all operations.
- Authentication
- Encryption
- Symmetric Keys
- Same key (KAB) used to both encrypt and decrypt a message
- E.g., DES (Data Encryption Standard): 56 b key operates on 64 b blocks from the message
- Public-Private keys
- Anything encrypted with KApriv can be decrypted only with KApub
- Anything encrypted with KApub can be decrypted only with KApri
- If Alice wants to send a secret message M that can be read only by Bob
- Alice encrypts it with Bob’s public key
- KBpub(M)
- Bob only one able to decrypt it
- KBpriv(KBpub(M)) = M
- Shared/Symmetric vs. Public/Private
- Shared keys reveal too much information
- Hard to revoke permissions from principals
- E.g., group of principals shares one key
- want to remove one principal from group
- need everyone in group to change key
- Public/private keys involve costly encryption or decryption
- At least one of these 2 operations is costly
- Many systems use public/private key system to generate shared key, and use latter on messages
- Shared keys reveal too much information
- Symmetric Keys
- Digital Signature/Certificate
- To sign a message M, Alice encrypts message with her own private key
- Signed message: [M, KApriv(M)]
- Anyone can verify, using Alice’s public key, that Alice signed it
- Digital Certificates implemented using digital signatures
- To sign a message M, Alice encrypts message with her own private key